Not clickbait!
Over the past few weeks we drastically improved our website. Add to cart latency went from an average of 4.2 seconds to under 1 second, page loading times have been cut in half, and our login flow no longer takes up to 10 seconds to log in.
The core of these speedups come from a massive reduction in processing latency on our backend for the service. Our server nodes has gone from taking an average of 3 seconds to process a request to literally milliseconds. There is a lot that went into this, so I’m splitting this into multiple parts.
I want to do a further deep dive into the infrastructure that powers Redux Robotic’s new website, so consider this part 1 of the making of Redux’s newsite. But it all starts with one critical service
Canandmiddleware
What is Canandmiddleware? In short, it’s the backend edge distributed service that handles connections to our site. At it’s core, its a middleware proxy, which takes requests and proxies them back to a number of services. The full breakdown in complicated, but approximately:
- 70% of requests go to BigCommerce, the commerce backend of the website
- 20% of the requests go to Directus, our Content Management system
- 5% of requests go to Stripe, our payment processor
- 5% of requests go to bot analysis, website performance tracking, or other security services.
Every request passes through Canandmiddleware, so it is extremely optimized at what it does. On average, a request spends under 10ms in the middleware software. So why are website loads so slow?
First problem: An average request to the BigCommerce API can take up to 5 seconds. So, we want to speed that up. How?
A simple answer is “just cache the requests!”
 This doesn’t work in practice though. One of the most intensive operations is cart operations (adding a product to cart especially), which cannot be cached; carts are unique per user.
This doesn’t work in practice though. One of the most intensive operations is cart operations (adding a product to cart especially), which cannot be cached; carts are unique per user.
Carts Are More Complicated Then You Think
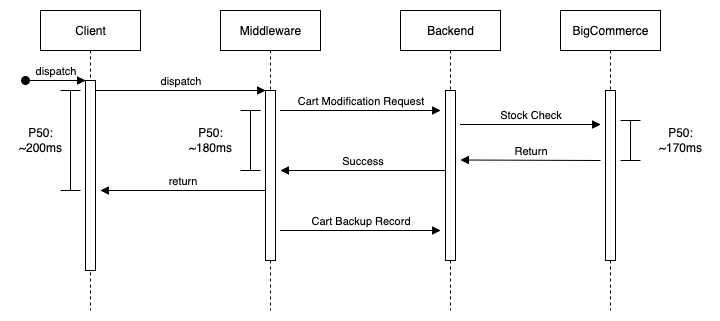
When you add something to your cart on an ecommerce store, a few things happen:
- The products to be added are checked for remaining availability
- If no existing cart exists with the session, a new cart is provisioned
- If the existing session is expired, a new session is created
- If the user is logged in, the cart is attached as metadata to their account
- A unique identifier representing the cart session is returned
- The new cart data (contents) is returned
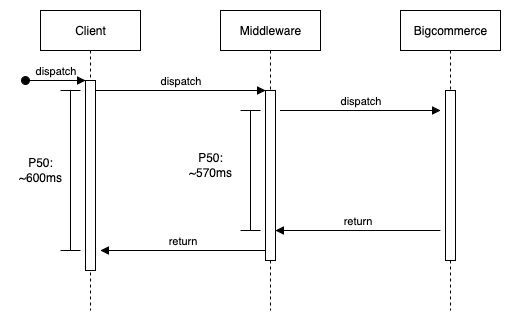
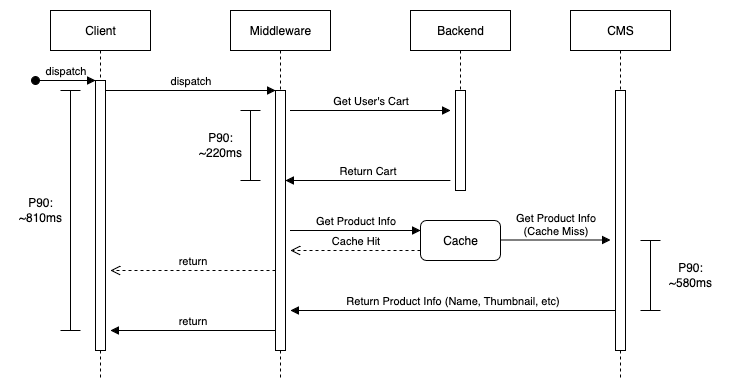
The existing add to cart system is pretty straightforward, with almost all of the latency coming from BigCommerce. There is some additional overhead then average in routing the request, due to sometimes needing to authenticate the user.
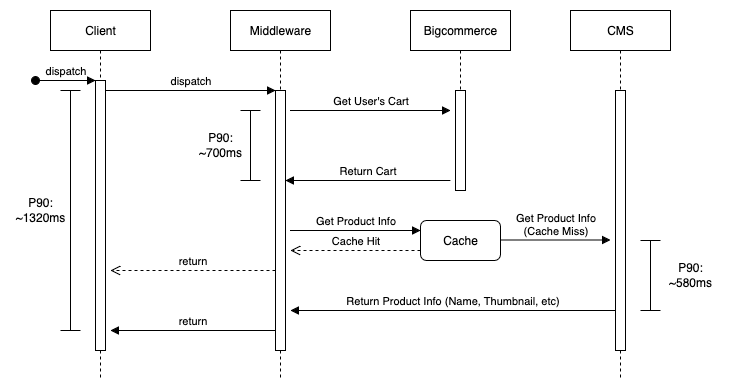
The cart fetch system is a little more complex, with added latency due to fetching product information from a CMS.
 BigCommerce centrally stores carts in their API, so any request involving carts have to go to their datacenters. They also require rapidly changing state, which means we can’t easily cache them, even with a distributed cache (which can take up to 60 seconds to become available). That means accelerating carts is more complex then static fetches, since we need a stateful cache middleware.
BigCommerce centrally stores carts in their API, so any request involving carts have to go to their datacenters. They also require rapidly changing state, which means we can’t easily cache them, even with a distributed cache (which can take up to 60 seconds to become available). That means accelerating carts is more complex then static fetches, since we need a stateful cache middleware.
Easier said then done though.
- We still need a immediately consistent way to check if a product is available in the quantities we need
- We need a eventually consistent way of attaching the cart to a customer
- We need a way to expire carts when not used for a long period of time
- We need a way of tracking cart identifiers and what carts they represent
Tackling this, a clear structure emerges:
- Cache cart operations in some sort of relational db
- Cache a customer UUID with the cart for lookup when logged in
- Have a periodic CRON job remove old carts
- Have some centralized service hold information about product quantities for add to cart gating
This lead to a very important decision for us to add a new service to the middleware: Canandbackend, our system to sit in front of BigCommerce to cache data itself. Canandbackend started with two main services: CartDB and CartManager.
CartDB
CartDB is a lightweight SQLite backed DB that runs on the edge, and stores the items in the user’s cart, and some metadata about the cart (last updated, created, etc). It is backed by Cloudflare Durable Objects, and inherently isn’t designed to be globally stateful, at any given time the only thing we can check is how many CartDB instances have been spun up (and their UUIDs), and an eventually consistent record of cart contents.
The edge server nodes are allowed to spin up CartDB instances as needed, but only the CartDB instance can delete itself (which it does after a period of time of inactivity). Since each CartDB instance is a micro-V8 container with a tiny SQLite file, it is inherently cheap to run. Storing 1000 users of carts under normal activity would cost under $1 per year.
CartDB is backed by a eventually consistent global SQL db, but largely rigourous data backup solutions aren’t required; if a datacenter causes data loss the most that will happen is a cart will be lost (annoying, but not p0). The micro instance is able to synchronize it’s state to the centralized DB after returning to the end user, so requests still appear on the edge.
CartManager
CartManager is the compliment to CartDB. It is a centralized monitor that polls the health of various carts, and automatically expires them after a given timeout. It also analyzes incoming connections to ensure that a rogue user isn’t spawning thousands of carts, and also allows for anonymous cart trend analysis. CartManager has no insight into the metadata that CartDB stores about the user in order to do user checks, and exists just to expire carts and allow for abondoned cart and cart error analysis. This is a huge change from our existing solution where information about the user and their cart activity is plainly detailed for us to see, and is a move towards our privacy focused vision for Redux Robotics.
CartManager exists in a single location, since users will never interact with it.
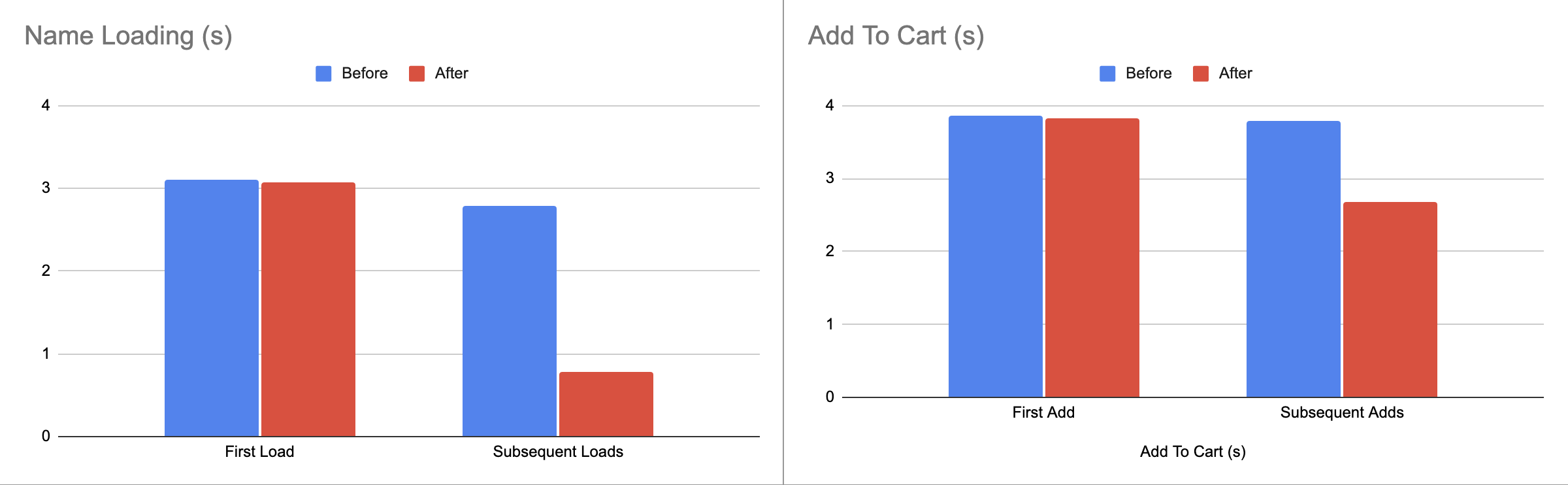
The Results
The results speak for themselves.
- P50 latency for add to cart reduced by 400ms
- P90 latency for add to cart reduced by 200ms
- P99 latency for add to cart reduced by 100ms
The largest gains for add to cart reduction are, unsurprisingly, in North America, specifically near US-EAST-1. I suspect this is because the stock check latency is a large contributing factor, and those requests generally seem to be proxied through North America. If only there was a way to make stock checks truely eventually consistent/globally replicated (coming soon).
 Just opening a browser, the difference is stark.
Just opening a browser, the difference is stark.
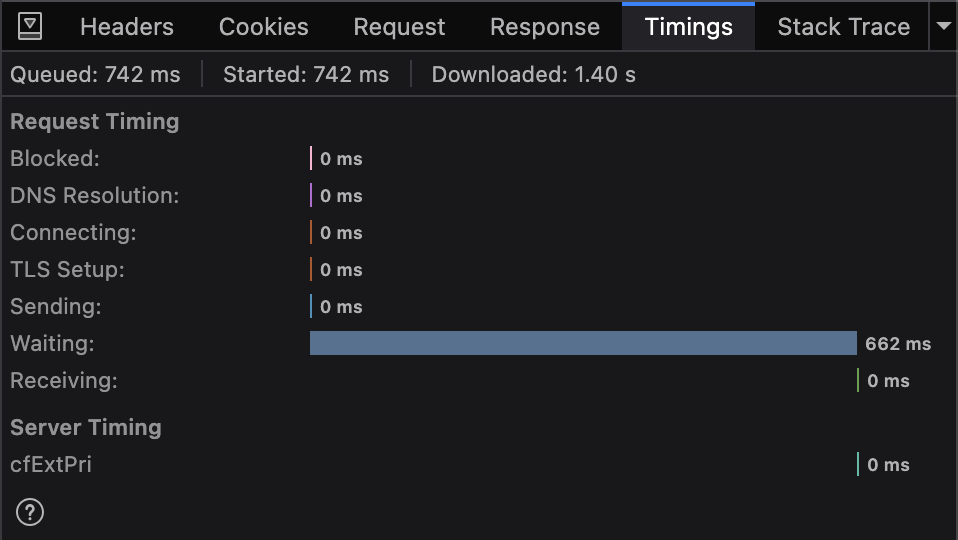
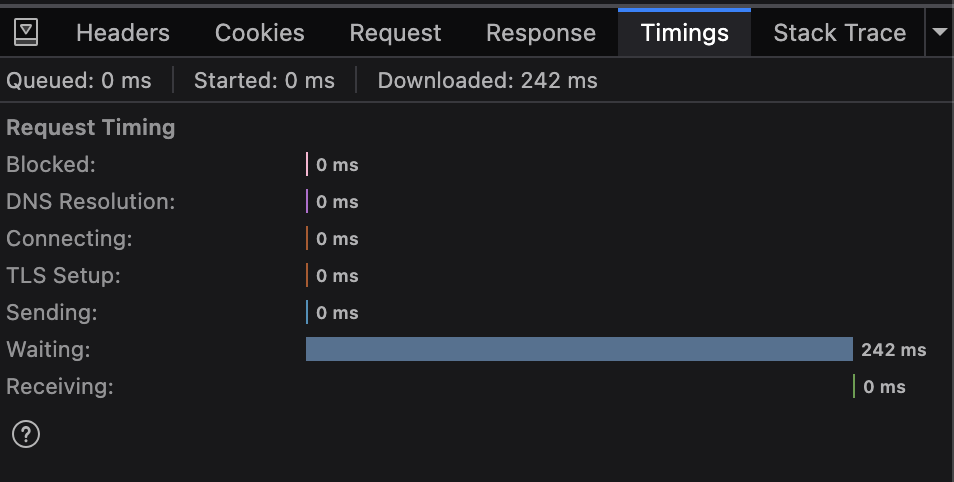 Add to cart latency is noticably lower. This is far beyond anything I expected, but the popup feels near instant.
Add to cart latency is noticably lower. This is far beyond anything I expected, but the popup feels near instant.
Getting cart data was also improved:
- P50 latency for get cart reduced by 430ms
- P90 latency for get cart reduced by 510ms
- P99 latency for get cart reduced by 35ms
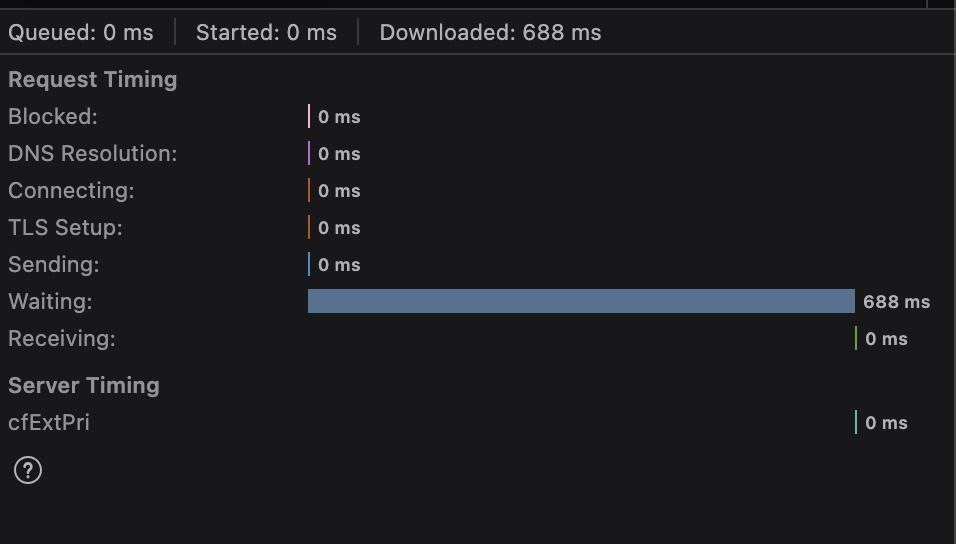
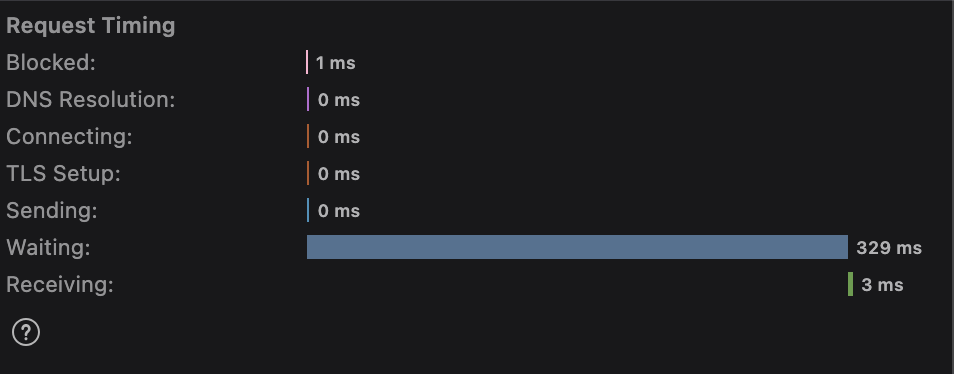 This is a little disappointing after seeing the results for add to cart. The P99 in particular is not great, it causes a pretty high latency contribution that makes it feel as slow as the old system. This shouldn’t be surprising though, considering the architecture.
This is a little disappointing after seeing the results for add to cart. The P99 in particular is not great, it causes a pretty high latency contribution that makes it feel as slow as the old system. This shouldn’t be surprising though, considering the architecture.
 Most of the latency savings is due to being able to peer the cart instance in the closest DB to the user. Since users don’t tend to move around a lot, this allows us to have large latency savings, but it also means there is still a fundamental latency limit from the CMS.
Most of the latency savings is due to being able to peer the cart instance in the closest DB to the user. Since users don’t tend to move around a lot, this allows us to have large latency savings, but it also means there is still a fundamental latency limit from the CMS.
Overall, this was a pretty good success to me. For most of our customers, the speedup was immediate and noticable. For international customers, there was still some speed improvements once the cache was warm, due to peering carts at datacenters near the user.
Reflections
I don’t think add to cart latency is a big factor in whether or not someone buys a product, but I think it’s useful to optimize websites where possible. A large part of internationalization is being able to peer data and systems at nearby datacenters. CartDB is largely not about the actual cart system itself, but a proof of concept of using micro-instances with a local persistant store to create stateful services at the edge near a user.
Next up is dealing with other systems to enable full global replication and serverless design, which will come in future blogposts. I definitely think the system is overengineered, but it does provide a decent amount of benefit to the end customer. Bit by bit, we are taking third party dependencies out of the equation and replacing them with serverless architecture, which increases both reliability and privacy for our customers.
Sometimes you just have to do things for the sake of doing things.